
최신 소식
초록
현재의 AI 패러다임은 데이터, 파라미터, 컴퓨팅을 통해 성능을 확장하는 대규모 언어 모델(LLM)이 지배하고 있습니다. 이러한 패러다임은 언어 작업에는 효과적이지만, 추론, 일관성 및 실제 세계와의 상호작용 측면에서 구조적 한계를 보입니다.
최근 Yann LeCun과 스타트업 Logical Intelligence는 에너지 기반 모델(EBM), 월드 모델(World Models), 그리고 모듈형 아키텍처에 기반한 다른 방향을 제시하고 있습니다. 본 기사는 왜 자기회귀(Autoregressive) 모델링이 AGI에 충분하지 않을 수 있는지, EBM이 추론을 어떻게 최적화 문제로 재정의하는지, 그리고 하이브리드 AI 스택이 어떻게 더 견고하고 제어 가능하며 일반화 가능한 지능 시스템을 가능하게 하는지에 대해 기술적으로 심층 분석합니다.
자기회귀 스케일링과 구조적 병목 현상
현대의 LLM은 조건부 확률 분포를 근사하는 자기회귀 모델입니다.
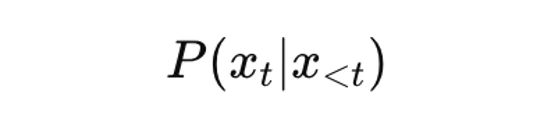 조건부 분포
조건부 분포 훈련 과정에서 대규모 말뭉치에 대한 교차 엔트로피 손실을 최소화하여 언어의 통계적 규칙성을 파라미터 모델로 압축합니다. 이 목적 함수는 다음 토큰 예측에는 매우 효율적이지만, 다운스트림 추론 작업에서 가시화되는 구조적 제약을 유발하며 자기회귀 모델 자체의 한계도 존재합니다.
첫째, 추론이 본질적으로 순차적입니다. 각 토큰은 이전에 생성된 토큰에 의존하며, 이는 노출 편향(Exposure Bias)과 오류 누적을 초래합니다. 생각의 연쇄(Chain-of-thought) 프롬프팅 같은 기술을 사용하더라도, 모델이 진정으로 "추론"하는 것이 아니라 그럴듯한 추론 흔적을 생성하는 것입니다. 최적화 목표가 솔루션의 타당성(전역적)이 아닌 토큰 수준의 확률(지역적)이기 때문에 이러한 흔적은 전역적 일관성을 보장하지 않습니다.
둘째, LLM은 명시적인 제약 조건 충족 메커니즘이 부족합니다. 논리적 규칙, 물리 법칙 또는 시스템 제약 조건은 가중치 내에 암시적으로만 인코딩됩니다. 이는 기호 추론, 계획 수립 또는 제약 하의 프로그램 합성 등 규칙에 대한 엄격한 준수가 필요한 작업에서 불안정성을 초래합니다.
셋째, 스케일링 법칙(Scaling Laws)에서 수확 체감의 법칙이 나타납니다. 파라미터를 늘리면 퍼플렉서티(Perplexity)는 개선되지만, 추론 정확도의 향상은 비선형적이며 종종 정체됩니다. 더 중요한 것은 컴퓨팅 비용이 초선형적으로 증가하여 지속적인 스케일링을 경제적, 환경적으로 어렵게 만든다는 점입니다.
엔지니어링 관점에서 핵심적인 한계는 이것입니다. 자기회귀 모델은 '정확성'이 아니라 '확률'을 최적화합니다. 이러한 불일치는 생성 작업에서 의사 결정 시스템으로 넘어갈 때 결정적인 문제가 됩니다.
더 알아보기: 순수 LLM의 필연적인 도태
통합 프레임워크로서의 에너지 기반 모델(EBM)
에너지 기반 모델(EBM)은 근본적으로 다른 공식을 제공하며 확률적 AI와 결정론적 AI 간의 차이를 보여줍니다. EBM은 확률 분포를 명시적으로 모델링하는 대신, 구성(configurations)에 대해 에너지 함수를 정의하고 최적화를 통해 추론을 수행합니다.
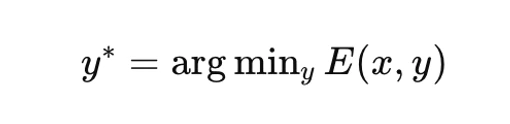 방정식
방정식여기서 E(x, y)는 입력 x와 후보 솔루션 y 사이의 학습된 호환성 함수입니다. 솔루션 $y$를 점진적으로 구성하는 자기회귀 디코딩과 달리, EBM은 $y$를 하나의 전체 객체로 취급하고 에너지를 최소화하는 구성을 탐색합니다.
이러한 변화는 몇 가지 심오한 시사점을 갖습니다.
-
표현과 추론의 분리: 모델은 에너지 지형을 학습하고, 추론은 경사 하강법, 랑제빈 동역학(Langevin dynamics) 또는 조합 탐색과 같은 최적화 방법을 통해 수행됩니다. 이를 통해 동일한 모델이 작업에 따라 여러 추론 전략을 지원할 수 있습니다.
-
제약 조건의 명시적 인코딩: 하드 제약 조건은 에너지 함수의 페널티 항으로 추가할 수 있고, 소프트 제약 조건은 데이터로부터 학습할 수 있습니다. 이는 타당성 조건이 충족되어야 하는 구조화된 문제에 EBM이 자연스럽게 적합하도록 만듭니다.
-
반복적 정제 지원: 자기회귀 디코딩처럼 초기 결정에 얽매이지 않고 시스템이 솔루션을 지속적으로 조정할 수 있습니다. 이는 자기 수정을 가능하게 하고 오류 전파를 줄입니다.
시스템적 관점에서 EBM은 연산을 생성 중심 파이프라인에서 최적화 중심 파이프라인으로 전환하며, 이는 고정밀 작업에서 더 효율적일 수 있습니다.
최적화 기반 추론 vs 샘플링
 LLM, EBM 및 월드 모델의 계층 및 기능
LLM, EBM 및 월드 모델의 계층 및 기능LLM과 EBM 사이의 중요한 엔지니어링적 차이는 추론에 있습니다.
LLM은 그리디 서치, 빔 서치 또는 뉴클리어스 샘플링과 같은 샘플링 기반 디코딩 전략에 의존합니다. 이러한 방법은 가장 가능성 있는 시퀀스를 근사하지만 제약 조건 충족을 보장하지는 않습니다. 빔 폭을 넓히면 탐색은 개선되지만 컴퓨팅 비용이 크게 증가합니다.
반면 EBM은 목적 함수를 직접 최적화하여 추론을 수행합니다. 이를 통해 시스템은 매 단계에서 전역 정보를 통합할 수 있습니다. 예를 들어, 계획 수립 작업에서 자원 제한, 시간적 의존성, 안전 조건과 같은 제약 조건을 최적화 과정에서 동시에 평가할 수 있습니다.
이러한 차이는 가능한 솔루션의 수가 기하급수적으로 늘어나는 조합 공간(combinatorial spaces)에서 특히 중요해집니다. 최적화 기반 접근 방식은 구조를 활용하여 더 빠르게 수렴할 수 있습니다.
하지만 EBM도 고유한 과제가 있습니다. 에너지 지형이 비볼록(non-convex)할 수 있어 지역 최적점(local minima)에 빠질 수 있습니다. 따라서 효율적인 최적화 절차를 설계하는 것이 중요하며, 실제로는 신경망이 탐색 과정을 안내하는 하이브리드 AI 아키텍처가 사용될 수 있습니다.
제약 조건 충족과 구성적 일반화
EBM의 가장 강력한 동기 중 하나는 제약 조건 충족 문제를 처리하는 능력입니다. 이러한 문제는 모델이 상호 작용하는 여러 조건을 만족하는 출력을 생성해야 합니다. LLM에서 제약 조건은 프롬프팅이나 미세 조정을 통해 간접적으로 강제되는데, 이는 취약하며 확장성이 떨어집니다. 반면 EBM은 제약 조건을 목적 함수에 직접 통합할 수 있어 더 신뢰할 수 있는 솔루션과 더 나은 구성적 일반화(Compositional generalization)를 가능하게 합니다.
구성적 일반화란 알려진 개념을 새로운 방식으로 결합하는 능력을 말합니다. LLM은 규칙 기반 추론보다는 패턴 매칭에 의존하기 때문에 종종 이에 어려움을 겪습니다. 구조화된 표현과 제약 조건 위에서 작동하는 EBM은 조합 전반에 걸쳐 일반화하는 데 더 유리한 위치에 있습니다. 엔지니어링 측면에서 이는 다음과 같은 영역에 중요합니다.
-
다중 제약 조건이 있는 스케줄링 시스템
-
물리적 제한이 있는 로보틱스 계획
-
기존 방정식이 있는 과학적 모델링
이러한 도메인에서 정확성은 선택이 아닙니다. 단 한 번의 위반으로도 전체 솔루션이 무효화될 수 있습니다.
월드 모델과 잠재 역학
얀 르쿤의 핵심 주장은 지능에는 언어 모델뿐만 아니라 월드 모델이 필요하다는 것입니다. 월드 모델은 환경 역학의 잠재 표현(latent representations)을 학습하는 것을 목표로 합니다. 기술적으로 월드 모델은 잠재 공간에서의 전이 함수 학습으로 볼 수 있습니다.
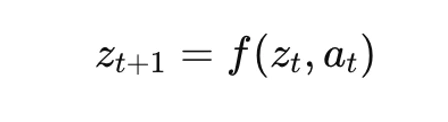 잠재 공간에서의 전이 함수
잠재 공간에서의 전이 함수여기서 zt는 잠재 상태이고 at는 행동입니다. 모델은 현재 상태와 행동이 주어졌을 때 미래 상태를 예측하는 법을 배웁니다. 이는 시뮬레이션을 통한 계획 수립을 가능하게 합니다.
토큰 공간에서 작동하는 LLM과 달리 월드 모델은 상태 공간에서 작동합니다. 이들은 관측 시퀀스(예: 비디오 프레임)로 훈련되어 시간적 구조를 학습하며, 이를 통해 인과관계와 물리적 상호작용을 포착할 수 있습니다.
EBM과 결합될 때 월드 모델은 물리 법칙이나 환경 역학에서 유도된 제약 조건을 제공할 수 있습니다. 이는 월드 모델이 결과를 예측하고 EBM이 제약 조건에 따라 후보 계획을 평가하는 강력한 루프를 형성합니다.
모듈형 AGI 시스템을 향하여
로지컬 인텔리전스가 제안한 아키텍처는 본질적으로 모듈형입니다. 단일 엔드투엔드 모델 대신 상호 작용하는 여러 구성 요소로 시스템이 이루어집니다.
-
LLM: 인터페이스 계층 역할을 하며 인간의 언어와 내부 표현 사이를 번역합니다.
-
EBM: 추론 계층 역할을 하며 최적화를 통해 구조화된 문제를 해결합니다.
-
월드 모델: 환경을 시뮬레이션하여 접지(grounding)를 제공합니다.
이러한 분리는 여러 엔지니어링적 장점을 제공합니다. 각 모듈은 서로 다른 목적 함수와 데이터셋으로 훈련될 수 있고, 전체 시스템을 다시 훈련하지 않고도 로컬 업데이트가 가능합니다. 또한 실패를 더 쉽게 격리하고 디버깅할 수 있습니다.
더 중요한 것은 이기종 컴퓨팅 전략이 가능하다는 점입니다. 예를 들어 LLM 추론은 조밀 행렬 연산에 최적화된 GPU에서 실행하고, EBM 최적화는 전문화된 솔버나 고전적 알고리즘을 활용할 수 있습니다.
시스템 수준의 과제와 미해결 문제
이러한 접근 방식은 유망함에도 불구하고 상당한 과제를 안겨줍니다.
주요 문제 중 하나는 통합입니다. 모듈 간 통신에는 잘 정의된 인터페이스와 공유 표현이 필요합니다. 특히 반복적인 최적화가 수반될 때 지연 시간(Latency)이 병목 현상이 될 수 있습니다.
또 다른 과제는 훈련 정렬(Alignment)입니다. 각 모듈이 서로 다른 목적을 최적화하여 잠재적인 충돌이 발생할 수 있습니다. 시스템이 일관되게 작동하려면 손실 함수와 상호 작용 프로토콜의 세심한 설계가 필요합니다.
EBM의 최적화 또한 쉽지 않습니다. 잘못 설계된 에너지 함수는 불안정한 동작이나 느린 수렴으로 이어질 수 있으며, EBM을 고차원 공간으로 확장하는 것은 여전히 활발한 연구 과제입니다.
마지막으로 데이터 문제가 있습니다. LLM은 대규모 텍스트 말뭉치의 이점을 누리지만, 월드 모델은 수집과 표준화가 더 어려운 고품질 멀티모달 데이터를 필요로 합니다.
더 알아보기: LLM 시스템에 실제로 필요한 데이터 파이프라인은 무엇인가?
결론
LLM의 지배력이 즉시 끝나지는 않겠지만, 그 역할은 재정의되고 있습니다. 얀 르쿤과 로지컬 인텔리전스가 강조했듯이, AGI로 가는 길은 순수 자기회귀 모델링에서 더 구조화되고 모듈화된 접근 방식으로의 전환을 요구할 수 있습니다.
엔지니어링 관점에서 핵심적인 변화는 확률적 생성에서 제약 조건 중심의 최적화로, 그리고 텍스트 기반 학습에서 세계에 접지된 모델링으로의 전환입니다. 이러한 변화는 새로운 과제를 불러오지만, 더 신뢰할 수 있고 해석 가능하며 진정한 추론이 가능한 시스템으로 가는 문을 열어줍니다.
이 방향이 성공한다면 미래의 AI 시스템은 단순히 그럴듯한 출력을 생성하는 것에 그치지 않고, 설계상 정확하며 현실에 근거하고 도메인 전반에 걸쳐 적응 가능한 솔루션을 계산해 낼 것입니다.
Newsletter
더 보기
























































































![[Recap] UPP Global Technology JSC Establishing Anniversary](/homepage/news-section/new-4.webp)




















































대화하기
원하신 정보를 이메일로 보내드립니다






이메일을 입력해 주세요
원하시는 내용을 입력해 주세요



Hanoi, Vietnam
Web3 Tower, No. 15, Alley 4, Duy Tan, Cau Giay, Hanoi, Vietnam